There's a reason that Benjamin Disraeli (or Mark Twain, take your pick, "That's a controversial issue....") said there are "Lies, Damn Lies and Statistics".
The number of ways of manipulating data and testing it to come up with a "statistically significant result" is huge.
So here is a very very simplified explanation of some of the things I've learned in the last 24 hours.
Mean: the sum of the observations divided by the number of observations.
Mode: the observation value that occurs the most often.
Median: the number separating the higher half of a sample from the lower half (in a list of numbers sorted in ascending order, it is the middle one, and if you have an even number of values then you take the mean of the two middle ones).
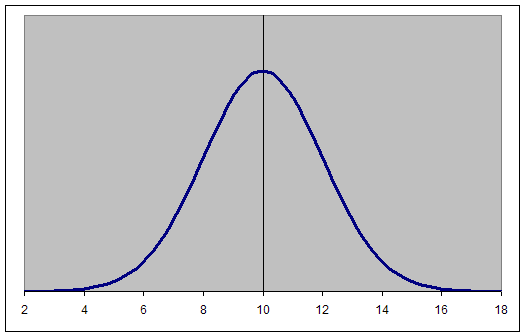
Normal distribution: the bell shaped curve, whose mean, median and mode are the same.
Skewed distribution: any curve which is not bell shaped.
Standard deviation: the square root of the variance. It is the root-mean-square (RMS) deviation of the values from their mean.
Variance: sum of the squares of the differences between each of the values and the mean of the values, divided by n-1 (where n is the number of values) (There is another formula for calculating variance, but this give the UNBIASED estimate - see here for a better explanation, but only if you've got your maths head on, otherwise just take it as read). It is a description of the amount of spread about the mean (a measure of central tendency).
In a normal distribution, 95.45% of values lie within 2 standard deviations of the mean.
Quantitative variables: Usually have a true zero (i.e. there is none of what we are counting).
- Continuous variable/data: can have any value within a given range (e.g. height, BMI)
- Discrete variable/data: can only have certain values (e.g. number of children (No 0.4 kids round here - Ed))
Qualitative variable/data: (as opposed to quantitative variable)
- Categorical variables/data: values are different classes or groups
- Nominal: no order (eye colour, race)
- Ordinal: ordered (first, second, third for example, or pain scores)
Ratio varaible/data: there is a true zero, for example temperature measured in Kelvin.
The distinction between the above two is this:
If I measure temperature in degrees celsius and then the temperature in degrees celsius doubles, then the temperature in Kelvin and degrees Fahrenheit does NOT double. Degrees Celsius is an interval variable, as is Fahrenheit, whereas Kelvin is a ratio variable.
Another example of a ratio variable is weight in kg and pounds. If you double your weight in stones and pounds, you double your weight in kg.
Yet another example: pH is NOT a ratio variable, because doubling your pH does NOT double your H+.
Range: difference between highest and lowest
Interquartile range: difference between values below which 25% lie, and above which 25% lie (so the range of the middle 50%).
Confidence interval: see here. (Also explains some of the other concepts!)
Okay, so now what about statistical tests:
Parametric tests: assumptions are made about the distribution (i.e. that it is normal and has constant variability, i.e. the variances of the two samples (or the standard deviations) are the same.
Non-parametric tests: make no assumptions.
Ordinal data or nominal data: Chi-squared
Normally distributed data (non-ordinal, non-nominal), two data sets: Student's t-test (paired or unpaired)
Normally distributed data (non-ordinal, non-nominal), more than two data sets: Analysis of variance (ANOVA) (paired or unpaired)
Non-normally distributed (non-ordinal, non-nominal), two data sets: Mann-Whitney U (or Wilcoxon Signed Rank if paired data (replaces paired Student's t-test)
Non-normally distributed (non-ordinal, non-nominal), more than two data sets, paired: Friedman's (don't ask, and don't look. The link is for completeness. You have been warned.)
Non-normally distributed (non-ordinal, non-nominal), more than two data sets, unpaired: Kruskal-Wallis (no, really, really don't ask, unless you have a real maths head. It is probably enough to know it is an extension of the Mann-Whitney U test).
Non-Normally distributed: "Oh Mann, I can't use the t-test" (Mann-Whitney U test) (Thanks to SR for this little "mnemonic")
Oh, and one last thing, if we take a number of samples from a population, and then we calculate the mean for each sample, plot this on a graph, we get a curve (with normal distribution) which has a standard deviation. This standard deviation is called the standard error of the mean. The smaller the standard error of the mean, the more closely the sample mean estimates the true population mean. Simple really!
Okay? So, that's it.
I'm not sure how much more I will write before the exam, but do keep coming back anyway, if you're a regular reader. If I pass, I'll pass on my knowledge, and if I fail, well, I'll be revising, so I'll pass on any other things I learn along the way! Feel free to leave suggestions or questions?!





{kind=link}
{kind=link}
1 comment:
Nice one on the statistics - we'll have to have a beer on Monday and self-congratulate on being the only two people sad enough to waste revision time by writing about revision (and proud of it!!).
Stay sane
James
Post a Comment